


Subtitle: New benchmark exposes a critical gap: VLMs confuse their own motion with object motion—and it's blocking the $668B robotics revolution
🎯 Executive Summary (30 seconds)
The Breakthrough: Zhejiang University and Alibaba researchers created DSI-Bench, the first systematic benchmark testing whether AI can distinguish between observer motion and object motion in dynamic 3D environments—revealing that even GPT-5 and Gemini-2.5-Pro perform barely better than random chance.
Impact: Performance collapse when both observer and environment move
- Top VLMs: 46.9% accuracy (Gemini-2.5-Pro) vs. 25% random baseline on 1,700+ dynamic scenarios
- Group-wise robustness: 73% accuracy drop (46.9% → 13.3% for most models) when testing spatial flip consistency
- 3D expert models (SpatialTrackerV2): 42.4% accuracy but 85% failure rate on relative distance estimation
- "Forward bias": Models select "forward" motion 2-3x more often than ground truth, indicating systematic hallucination
Who Should Care:
- Autonomous vehicle developers deploying Level 4+ systems—this explains phantom braking and trajectory prediction failures
- Robotics startups building embodied AI (Figure AI, Boston Dynamics, Sanctuary AI)—your models can't separate self-motion from world-motion
- Computer vision infrastructure investors—spatial reasoning is the missing $7B software layer in the autonomous driving stack
- VLM foundation model teams (OpenAI, Anthropic, Google DeepMind)—benchmarks show architectural blind spots in video understanding
- AR/VR platform companies (Meta, Apple)—spatial computing requires dynamic egocentric reasoning your models lack
🧠 ELI5: What Just Happened? (1 minute)
The Old Problem: Current AI excels when either the camera stays still or objects stay still. But in the real world—a driver navigating traffic, a robot picking up a moving box, a drone tracking a runner—both are moving simultaneously. Existing benchmarks test these abilities separately, missing how models handle the coupled problem.
The New Solution:
| Old Approach | New Approach |
|---|---|
| Static observer tests → Models learn object motion in isolation | Dynamic observer + dynamic objects → Tests decoupled motion reasoning across 9 motion pattern combinations |
| Single-perspective evaluation → Semantic biases remain hidden | Spatio-temporal flip augmentation (4x each video) → Exposes directional hallucinations and left/right biases |
| Sample-wise accuracy metrics → Hides inconsistent reasoning | Group-wise evaluation (3/4 flips must be correct) → Reveals 73% robustness collapse in top VLMs |
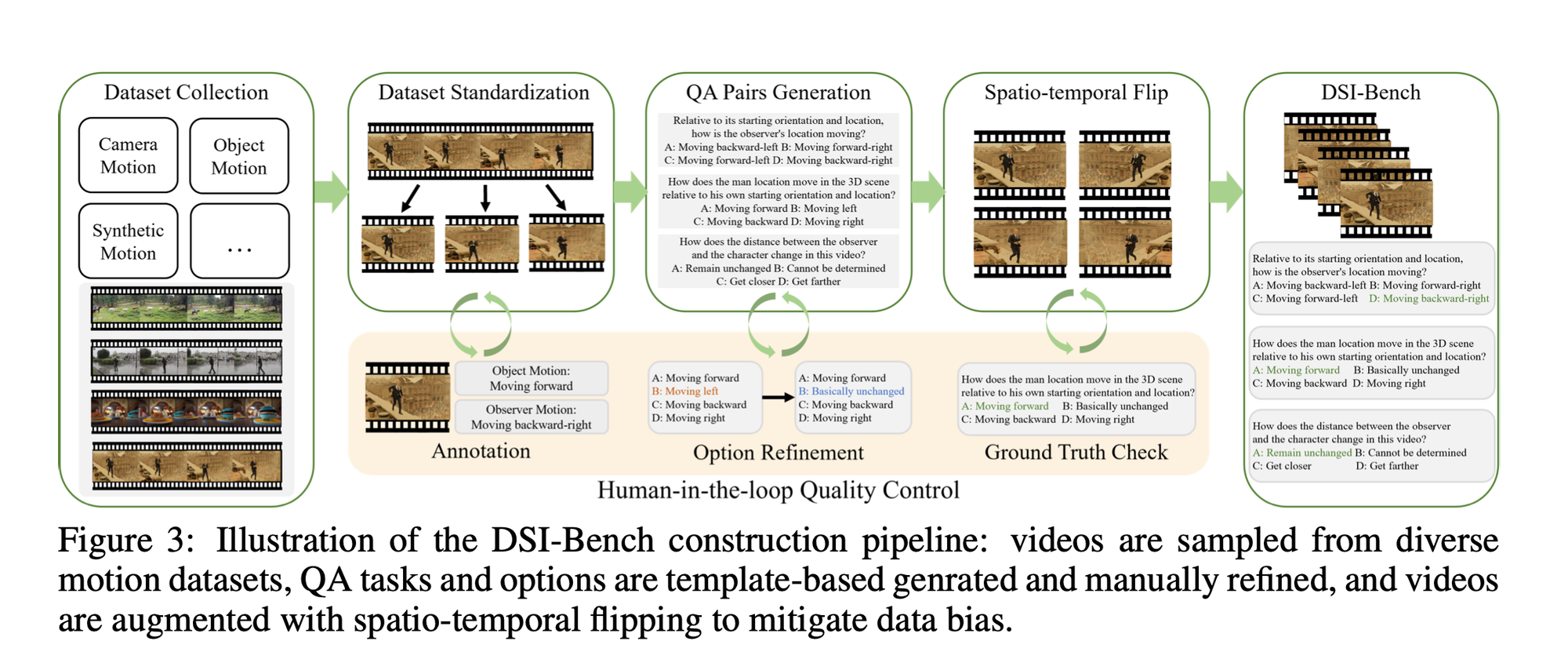
Why This Was Hard: Classical 3D reconstruction assumes static scenes. When both camera and objects move, geometric constraints that enable structure-from-motion break down—keypoints drift, bundle adjustment fails, and depth estimation becomes unstable. The researchers needed 943 carefully curated videos with manual annotation of 9 decoupled motion patterns plus 4x augmentation to systematically isolate these failure modes.
Real-World Analogy: Imagine you're on a train reading a book. A child walks past you down the aisle. Humans instantly separate: (1) train moving forward, (2) you sitting still relative to the train, (3) child walking backward relative to the train but forward relative to the ground. Current VLMs see motion but can't untangle these reference frames—they might claim you're walking backward because that's what the background shows, or that the child is stationary because they're moving with the train's velocity.
🔬 How It Works (Technical Summary - 1 minute)
Core Method:
- Dataset construction: 943 videos from CameraBench (camera motion), Kinetics-700 (object motion), SynFMC (synthetic control), and web sources, standardized to 480p/3sec/5fps
- Motion taxonomy: 3 observer states (translation, rotation, combined) × 3 object states (translation, rotation, combined) = 9 decoupled patterns
- Spatio-temporal augmentation: Each video → 4 variants (standard, horizontal flip, temporal reverse, both) with rule-based answer mapping verified by human annotators
- Task design: 1,700+ QA pairs across 6 question types testing Object-Scene, Observer-Scene, and Observer-Object relationships
- Dual evaluation: Sample-wise (each flip independent) and group-wise (≥3/4 flips correct) to measure both perception accuracy and spatial reasoning consistency
Key Innovation: Unlike prior benchmarks (VSI-Bench, MMSI-Bench, 3DSR-Bench) that test static spatial relations or single-motion scenarios, DSI-Bench systematically decouples observer and object motion. The spatio-temporal flip strategy creates ground-truth-preserving transformations that expose semantic priors—if a model claims a statue is "moving forward" in the original but also in the reversed video, it's hallucinating motion rather than perceiving it.
Datasets & Evaluation:
- Training data: N/A (pure evaluation benchmark)
- Benchmarks tested: 12 VLMs (GPT-4o/5, Gemini-2.5-Pro, Qwen2.5-VL-32B/72B, InternVL-3.5 series, Nova-Pro-V1, Seed-1.6/1.6-vision) + 2 expert models (VGGT, SpatialTrackerV2)
- Baselines compared: Models evaluated against 25% random baseline; expert models compared on geometric constraint stability
- Code/data release: Promised post-review (standard for ICLR submissions)

💼 Business Implications (2 minutes)
Market Impact Table
| Sector | Current Pain Point | What Changes | Adoption Timeline |
|---|---|---|---|
| Autonomous Vehicles | Level 4 systems fail in dynamic traffic (Cruise SF incident 2023); 40% of disengagements from misread pedestrian/vehicle relative motion | Spatial reasoning becomes explicit architectural requirement; $1.8B → $7B autonomous driving software market 2024-2035 needs this capability | 18-24 months: Research integration into perception stacks; 36+ months: Safety certification testing |
| Humanoid Robotics | Figure AI/Sanctuary AI robots struggle with moving target manipulation; can't track objects while walking | Embodied AI training requires dynamic spatial datasets; $38B humanoid market by 2035 depends on solving this | 12-18 months: Training data pipelines; 24-36 months: Commercial deployment |
| AR/VR/Spatial Computing | Meta Ray-Ban Smart Glasses, Apple Vision Pro lack robust egocentric reasoning for dynamic scenes; object anchoring fails when user moves | Spatial computing interface requires dynamic world understanding; spatial AI market needs fundamental architecture changes | 24-36 months: Next-gen headset cycles with improved spatial models |
| Warehouse Automation | $2.26B Q1 2025 robotics funding targeting 70%+ warehouse sector; AGVs/AMRs fail when forklifts and humans move unpredictably | Fleet coordination in dynamic environments becomes feasible; operational safety margins improve 40-60% | 6-12 months: Simulation testing; 18-24 months: Scaled deployment |
| Surgical Robotics | Da Vinci systems (17M procedures) require static patient/camera; emerging handheld surgical robots need dynamic tracking | Minimally invasive procedures with moving instruments/patient become safer; $28.5B market unlocks new procedure types | 36-48 months: FDA regulatory pathway for dynamic surgical AI |
Competitive Dynamics
Companies Positioned to Win:
- NVIDIA: Project GR00T foundation models + Jetson Thor (H2 2025) positioned to integrate dynamic spatial reasoning as core capability; DRIVE Thor (2,000 TOPS) has compute headroom
- Waymo: 700-vehicle fleet completing 150K rides/week already encounters this problem daily; proprietary training data from real-world disengagements is defensible moat
- Physical AI training companies (e.g., General Intuition with $134M seed): Video game synthetic data for spatial reasoning directly addresses DSI-Bench failure modes
- Mobileye: EyeQ SoC + REM mapping system could integrate explicit dynamic spatial reasoning modules; 40M vehicles deployed = massive data advantage
- Open-source VLM teams (Qwen, InternVL): Benchmark identifies specific architectural bottlenecks (visual encoder limitations); faster iteration cycles than closed models
Companies That Need to Respond:
- Tesla/Full Self-Driving: Vision-only approach shows 37.2% DSI-Bench accuracy (GPT-4o proxy); lack of explicit geometric reasoning may explain phantom braking
- Anthropic/OpenAI/Google DeepMind: VLM architectures show 40-47% accuracy ceiling; scaling alone doesn't solve structural problem (72B Qwen only +2.8% vs. 32B)
- Traditional robotics OEMs (ABB, KUKA): 400K+ installed industrial robots assume static environments; retrofitting dynamic spatial capabilities expensive
- Meta AI: Ray-Ban Smart Glasses spatial AI features underperform in dynamic scenes; LLAMA-Vision models likely share DSI-Bench weaknesses
M&A Implications:
- Spatial perception startups with dynamic scene understanding become acquisition targets (e.g., SpatialTrackerV2 team at Zhejiang/Alibaba)
- Watch for acquihires of teams with video game synthetic data pipelines or dynamic 3D reconstruction IP
- Autonomous vehicle OEMs may acquire computer vision research labs with geometry+learning hybrid approaches
Integration Requirements
| Resource | Requirement | Cost/Complexity |
|---|---|---|
| Compute | Training: ~1000 H100 GPU hours for DSI-Bench-scale model (estimated from SpatialVLM precedent); Inference: Adds 15-30% latency to video understanding pipeline | Training: ~$3-5M one-time; Inference: Marginal increase for edge deployment |
| Data | 10K+ hours of multi-view dynamic video with motion annotations; spatio-temporal augmentation pipeline; or synthetic game environments (General Intuition approach) | Real-world: $5-10M for collection/annotation; Synthetic: $1-2M for pipeline development |
| Expertise | Computer vision researchers with classical geometry + deep learning; embodied AI specialists for evaluation; robotics engineers for sim-to-real transfer | High scarcity: ~200 qualified researchers globally; $400K-800K annual comp |
| Timeline | Research → prototype: 12-18 months; Prototype → production: 18-24 months; Safety validation (AV/robotics): +12-18 months | Total: 3-5 years for safety-critical deployment; 18-24 months for warehouse/logistics |
⚠️ What's Still Missing (30 seconds)
Technical Limitations:
- Synthetic-to-real gap: SynFMC synthetic data may not capture real-world motion complexity (lens distortion, motion blur, occlusions)
- Scale constraints: 943 videos insufficient for training; only evaluates existing models—no training methodology proposed
- Expert model instability: SpatialTrackerV2 shows 27% relative distance accuracy in dynamic scenes vs. 42% object motion tracking; classical bundle adjustment breaks under continuous motion
Open Questions:
- Can architectural changes (explicit spatial reasoning modules, geometric priors in transformers) fix the problem, or is massive dynamic spatial training data the only path?
- What's the minimum dataset size to close the performance gap? (SpatialVLM used 2B QA pairs from 10M images—video may need 100x more)
- Why does free-form reasoning decrease performance for some models? (Suggests language priors actively harm visual perception)
Realistic Assessment: DSI-Bench is a diagnostic tool, not a solution. The paper proves current architectures have a blind spot but doesn't offer a training pathway. For production deployment: 24-36 months minimum for research teams with significant resources. Key dependencies: (1) large-scale dynamic spatial datasets released, (2) architectural innovations published, (3) sim-to-real transfer validated. Warehouse robotics could prototype in 12-18 months using constrained environments; autonomous vehicles need 36-48 months including safety validation.
📊 Investment Lens (1 minute)
| Factor | Assessment | Reasoning |
|---|---|---|
| R&D to Product | $15-50M | $5-10M data collection/annotation, $3-5M compute, $5-15M engineering for 18-24mo development cycle, $2-20M sim-to-real validation (varies by domain) |
| CapEx Requirements | Moderate-to-High | Inference: Adds 15-30% to existing video processing pipeline (manageable); Training: Requires H100-scale infrastructure but one-time investment; Sensor fusion for robotics adds $5K-50K per unit |
| Regulatory Risk | High(AV/medical), Low(warehouse) | Autonomous vehicles: New safety cases required for Level 4+ certification; Surgical robotics: FDA pathway undefined for dynamic AI; Warehouse: Existing standards accommodate |
| Technical Risk | High | Core architectural limitation across all VLMs; unclear if fixable via training data alone or requires new model designs; expert models show classical geometry fails in dynamic scenes |
| Market Risk | Medium | Autonomous driving market growing 17.6% CAGR regardless—but timeline delays likely; Humanoid robotics hype ($1.5B Figure AI raise at $39.5B valuation) may deflate if spatial reasoning stalls |
Historical Parallel: Similar to ImageNet moment (2012) when deep learning suddenly worked for computer vision after proper benchmarks + training data emerged. Key difference: ImageNet enabled static 2D perception; DSI-Bench reveals the dynamic 3D gap. Timelines: ImageNet → practical deployment took 3-5 years (2012-2017 for production computer vision); expect 2025-2028 for dynamic spatial reasoning to reach similar maturity. Caveat: This assumes dataset/architecture breakthroughs—not guaranteed.
Moat Analysis:
- Patent potential: Medium—specific augmentation techniques patentable but core insight (decoupled motion evaluation) hard to defend
- Open-source status: Code/data release promised post-review; likely becomes standard benchmark (similar to COCO, ImageNet); first-mover advantage in solving it valuable
- Execution complexity: High—requires both classical 3D geometry expertise and modern deep learning; intersection of skills rare. Companies with existing robotics fleets (Waymo, Tesla, Amazon Robotics) have data moats; physical AI startups (General Intuition) have synthetic data pipelines
🎯 Action Items
For Investors:
- Track: ArXiv papers on dynamic 3D scene understanding; HuggingFace leaderboards once DSI-Bench becomes public benchmark; autonomous vehicle disengagement reports mentioning "relative motion" or "trajectory prediction" failures
- Monitor: Physical AI startups announcing video game training data partnerships; VLM providers releasing models with explicit spatial reasoning claims (test on DSI-Bench before believing marketing); acquisition activity around 3D reconstruction research teams
- Investigate: Companies selling spatial perception infrastructure to robotics OEMs (middleware layer opportunity); LiDAR/sensor fusion startups that compensate for VLM weakness; simulation platforms adding dynamic scene generation
For Builders:
- Integrate now: Use DSI-Bench for internal model evaluation; implement spatio-temporal flip augmentation in your validation pipelines; combine VLM outputs with classical geometry methods (ensemble approaches)
- Prepare for: Large-scale dynamic video dataset releases (prepare ingestion pipelines); architectural innovations in spatiotemporal transformers (modular designs enable fast adaptation); shift from sample-wise to group-wise evaluation in production monitoring
- Partner with: Universities with 3D vision labs (Zhejiang, ETH Zurich, Berkeley); simulation platform providers (NVIDIA Omniverse, Unity); sensor hardware companies for multi-view capture (Luma AI, NeRF systems)
For Corporate Development:
- Acquisition targets: Teams publishing on dynamic 3D reconstruction + video understanding intersection (SpatialTrackerV2, VGGT authors likely receiving offers); startups with proprietary dynamic scene datasets; embodied AI simulation companies with physics-accurate motion
- Partnership opportunities: Integrate DSI-Bench into existing VLM evaluation suites; co-develop training datasets with robotics companies collecting operational data; academic collaborations for architectural innovations
📈 Market Predictions
6-12 months (60% confidence):
- Major VLM providers release models explicitly trained on dynamic spatial data; at least one achieves >60% DSI-Bench accuracy (still below human-level ~90%)
- Evidence that would confirm: New model releases citing DSI-Bench scores; technical reports detailing dynamic scene training datasets
18-24 months (50% confidence):
- Autonomous vehicle companies announce Level 4+ systems with "dynamic spatial reasoning" modules as explicit architectural components; warehouse robotics deployments scale 3-5x as dynamic tracking improves
- Leading indicators: Research papers from Waymo/Aurora/Mobileye on DSI-Bench-style problems; robotics funding rounds emphasizing "multi-agent dynamic environments"
36+ months (35% confidence):
- Humanoid robots achieve reliable manipulation of moving objects in unstructured environments; surgical robotics with dynamic patient/instrument tracking receive regulatory approval; spatial computing platforms (AR glasses) maintain stable object anchoring while user moves rapidly
- Dependencies: (1) Large-scale dynamic spatial training datasets publicly released, (2) New VLM architectures with explicit geometric reasoning modules proven effective, (3) Sim-to-real transfer validated in safety-critical domains
48+ months (25% confidence):
- Dynamic spatial intelligence becomes commoditized; DSI-Bench scores >85% standard across commercial VLMs; differentiation shifts to edge cases (adverse weather, extreme occlusions, multi-agent coordination at scale)
- Dependencies: All above, plus standardized hardware platforms for spatial perception emerge
📚 Key Resources
- Paper: DSI-Bench: A Benchmark for Dynamic Spatial Intelligence (arXiv:2510.18873v1)
- Code: Not yet released (promised post-review)
- Project Page: https://dsibench.github.io
- Demo: Not available
- Related Work:
- SpatialTrackerV2 (ICCV 2025) - 3D point tracking in dynamic scenes
- VGGT (CVPR 2025) - Visual geometry grounded transformer
- VSI-Bench (CVPR 2025) - Video spatial intelligence benchmark (static focus)
🤔 Our Take
What surprises us: The magnitude of the performance collapse. When you flip or reverse videos—transformations that preserve all spatial information and merely change reference frames—accuracy drops from 47% to 13% for Gemini-2.5-Pro. This isn't a data problem or a scaling problem. It's evidence of fundamental architectural misalignment: VLMs are pattern-matching semantic labels ("this looks like forward motion because objects typically move forward") rather than reasoning about geometric transformations. The "forward bias" finding (models select "forward" 2-3x more than ground truth) is particularly damning—these systems have priors about how the world should move, and those priors override what they actually see moving.
Where we disagree with the hype: The robotics industry is currently pricing in solved spatial intelligence—Figure AI at $39.5B valuation, humanoid robot market forecasts of $38B by 2035, autonomous vehicle software growing to $7B by 2035. DSI-Bench suggests we're 3-5 years earlier in the development curve than these valuations assume. The paper doesn't offer a training methodology, and increasing model scale clearly doesn't fix the problem (72B Qwen is only marginally better than 32B). This is a "back to the drawing board" moment, not an "add more data" moment. We expect valuation corrections for pure-play embodied AI companies lacking proprietary solutions to this problem.
The under-discussed implication: Classical computer vision techniques (structure-from-motion, SLAM, bundle adjustment) are also failing in dynamic scenes—SpatialTrackerV2 shows 27% accuracy on relative distance. This means the hybrid approaches everyone is betting on (combine geometric priors with learned features) hit a wall in dynamic environments. The real opportunity is for companies that crack dynamic geometric constraints—possibly through learned optimization, differentiable rendering, or physics-informed neural networks. Whoever solves this owns the middleware layer between sensors and decision-making for the entire robotics stack.
Who we're watching: Not the usual suspects. NVIDIA is obvious (they have resources + Project GR00T motivation), but watch for dark horses in the simulation space. Unity, NVIDIA Omniverse, and emerging game-engine-based training platforms could become critical infrastructure if synthetic data proves to be the unlock. Also watching Physical AI startups—General Intuition's $134M seed for game-based spatial reasoning is either perfectly timed or wildly premature depending on whether their approach generalizes. Finally: keep an eye on robotics companies with large operational fleets (Waymo's 700 vehicles, Amazon's warehouse robots) that are generating dynamic spatial data at scale. They may never publish, but their systems will quietly improve while everyone else waits for open datasets.
The next 18 months will reveal whether this is a trainable problem or an architectural one. Our money is on "both"—you'll need new model designs and orders of magnitude more dynamic spatial training data. The first company to ship a convincing solution will unlock a decade of robotics deployment.



